代理类型(proxy):透明代理 匿名代理 混淆代理和高匿代理 这里写一些python爬虫使用代理的知识, 还有一个代理池的类 方便大家应对
在做网站项目时,经常会使用脚本生成sitemap, 便于爬虫爬取,有利于SEO。 那么如何使用Python来生成sitemap呢?下面我们来研究一番。安
用python实现的抓取腾讯视频所有电影的爬虫(文章不错,所以进行了转载)# -*- coding: utf-8 -*-import reimport urllib2from bs4...

在python爬虫爬取某些网站的验证码的时候可能会遇到验证码识别的问题,今天就来看下如何让机器自动识别验证码。 识别验证码通常是这几个步骤: 1、灰度处理 2、二值化 3、去除边框
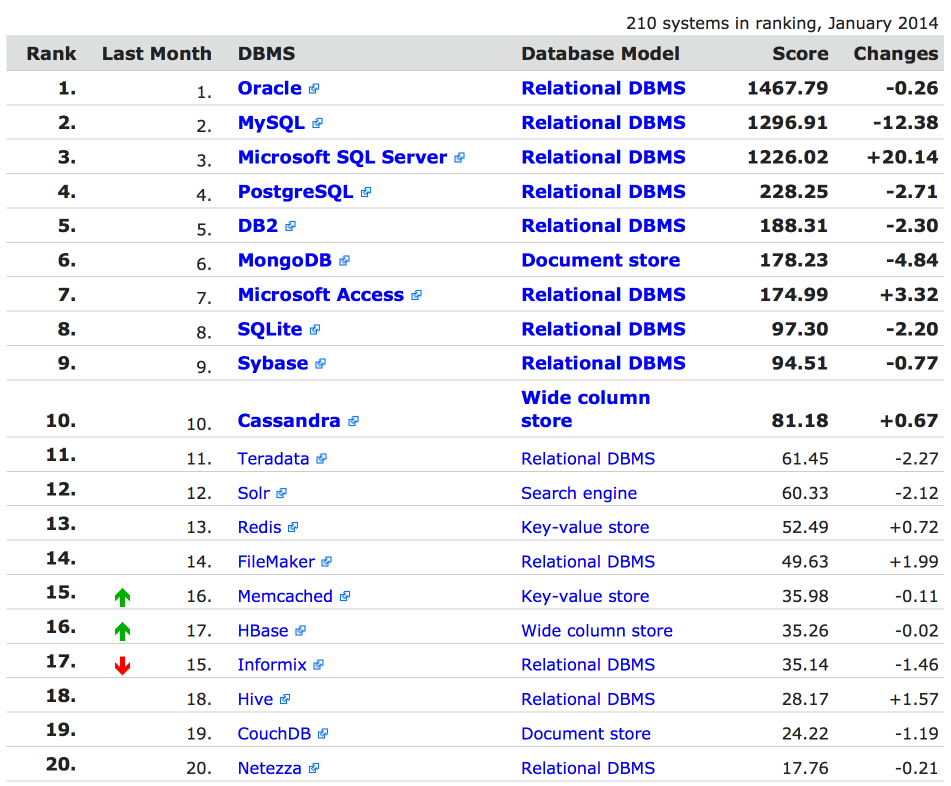
DB-Engines 发布2014年1月份的全球数据库排名,前 20 名数据库如下表所示:同时 DB-Engines 也发布了年度数据库 —— MongoDB。Mong
说道爬虫大家或许感觉非常神秘,其实它没有我们想象的那么神奇(当然,google和baidu的爬虫是一场复杂和强大的,它的强大不是爬虫本身强大...
多线程概述多线程使得程序内部可以分出多个线程来做多件事情,充分利用CPU空闲时间,提升处理效率。python提供了两个模块来实现多线程threa
在开发自用爬虫过程中,有的网页是utf-8,有的是gb2312,有的是gbk,如果不加处理,采集到的都是乱码,解决的方法是将html处理成统一的utf-8
php的引用就是在变量或者函数、对象等前面加上&符号。在PHP 中引用的意思是:不同的名字访问同一个变量内容。与C语言中的指针是有差别的,
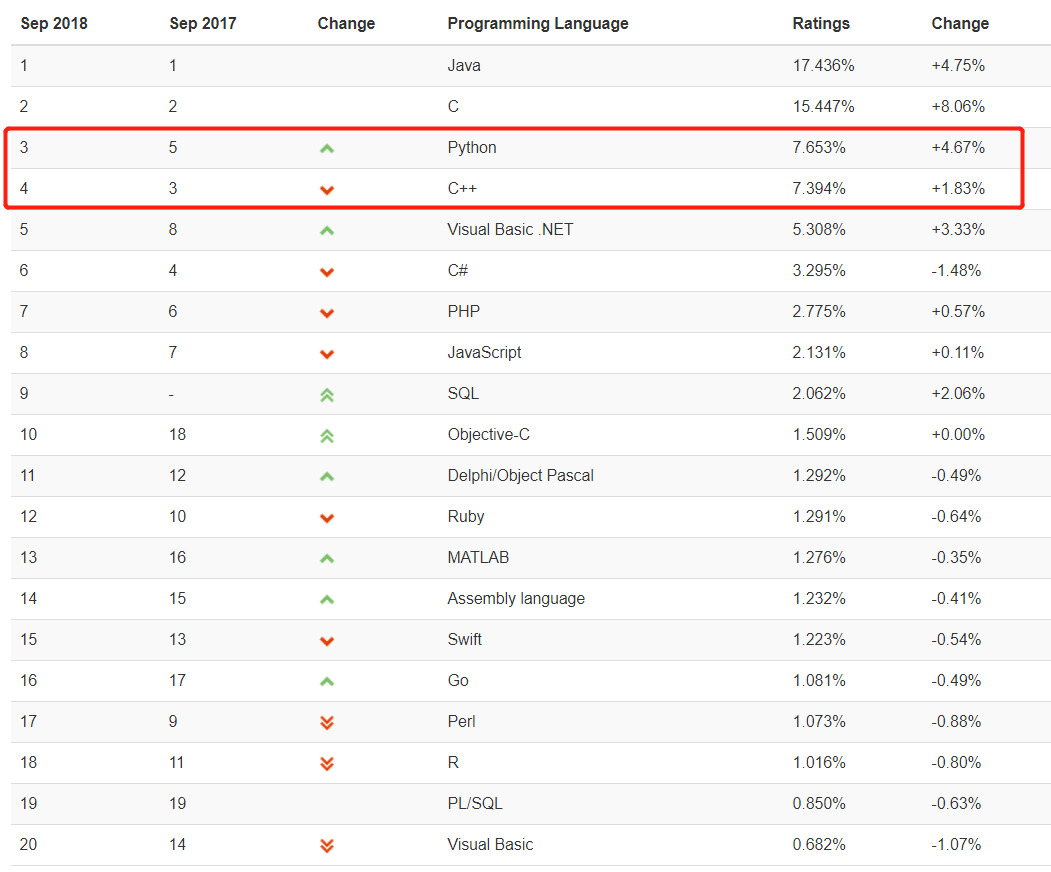
TIOBE 发布了 9月份的编程语言排行榜,上个月 Python 与第 3 名擦肩而过,而指数稳步上升的它在本月终于打败 C++,成功探花。“人生